
Uncategorized
Quality of life declined during pandemic, survey says
The average quality of life across Canada declined this year during the COVID-19 pandemic, a survey says.
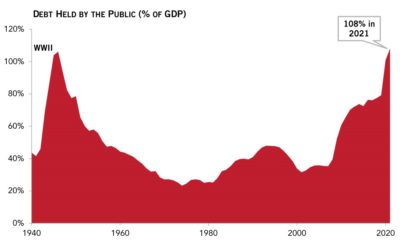
The survey taken by Stats Canada found that average life satisfaction declined from an average of 8.1 out of 10 in 2018 to 6.7 in 2020. Measuring the “finances, health and social contacts” of Canadians, it is the lowest quality of life recorded since the survey began in 2003.
From the initial closure of non-essential businesses in March 2020 to the current stay-at-home order in Ontario in effect since Jan. 14, CBC reports the economy is trying to recover with around two to three million jobs lost during the first wave of the pandemic.
Despite the federal government’s efforts to procure COVID-19 vaccines Maj.-Gen. Dany Fortin, appointed to oversee vaccine distribution, said at a press conference on Jan. 15 that due to renovations at Pfizer’s factory in Belgium, deliveries of the Pfizer-BioNTech vaccine would be delayed and reduced until early February.
Citing shortening supplies provincially at a Jan. 19 press conference, Doug Ford, premier of Ontario, expressed concern over the shortages and the effects on vaccination timelines as, “the vaccine is the difference between life and death for the most vulnerable,” he said.
This comes as Dr. Theresa Tam, chief public health officer, said at another Jan. 15 press conference that a surge in cases is due in part to the holiday season.
“Unless public health measures are further intensified, we will not be able to sufficiently suppress the current rate of epidemic growth,” she said.







The phrase “data is all around us” is thrown around often when you first start data journalism or data science. While data is indeed all around us, from social media statistics to daily weather fluctuations, most of the time, it’s difficult, if not impossible to download, clean and analyze as a journalist without a strong technical background.
For me, a student journalist who almost failed out of her first-year computer science class, web scraping was a data journalism skill I never thought I would take up. Open source government data in clean spreadsheets seemed to be the extent of the data I would work on. However, over the past few weeks, I learned how to write a small piece of Python code that helped me scrape some data I had been searching for from a government website.
While I still have a lot to learn and do for this project, being able to write this program from scratch and have it actually give me the output I needed was incredibly rewarding. This piece will take you step-by-step through web scraping process.
What is web scraping?
Dictionary.com defines web scraping as “the extraction and copying of data from a website into a structured format using a computer program.”
On web pages, there is text, images, tables, lists, links and other elements that you can scrape using code. Web pages are made up of hypertext markup language (HTML) that you can scrape from. For example, you can scrape tables off of Wikipedia pages, which are denoted with the <table></table> tags.
These two web pages are examples of pages that can be scraped for data, relatively easily, using code.
Web scraping code will identify the page or pages you’re looking to extract from, grab the data you want and then save it in a “structured format” such as a CSV file. The purpose of web scraping is to get data that exists on a website into a file on your computer that you can analyze more easily.
Web scraping is useful when you can find the data you want on a website, but it’s not available to download or not available to download in a file you want. For example, you might want to scrape a simple table off of a website that isn’t available to download. Or in my case, you want to scrape multiple PDF files and save them as a different type of file.
The process of web scraping, as described by Dataquest.io is as follows:
- Request the content (source code) of a specific URL from the server
- Download the content that is returned
- Identify the elements of the page that are part of the table we want
- Extract and (if necessary) reformat those elements into a dataset we can analyze or use in whatever way we require.
What I’m working on
When I was working on my previous story on North Shore Rescue’s record-breaking 2020 year, I was trying to find search and rescue statistics from 2020, including which parks or areas saw the most calls.
Unfortunately, they didn’t have this information published anywhere, but they did have comprehensive data on every search and rescue mission that happened. However, it was all stored in PDFs.
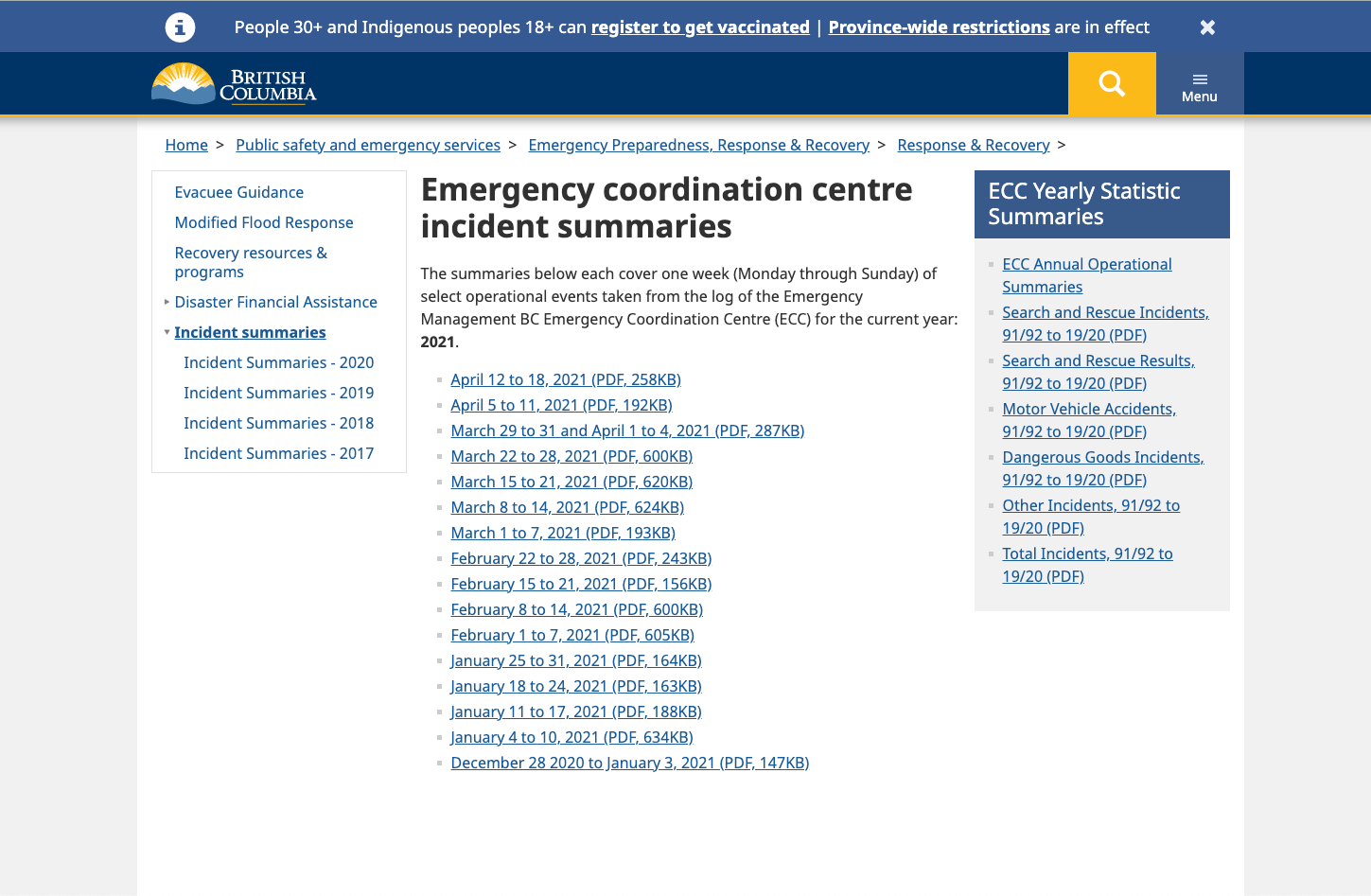
Every week, Emergency BC releases a weekly incident report on their website that lists out all the emergency-related incidents, including search and rescue missions, that occurred in the past week. These reports are kept as PDF files on the website which anyone can download. However, PDFs are virtually useless for data analysis purposes–we want them in a machine-readable format, such as a CSV file.
My web scraping goal became this: Download every PDF on the webpage and convert them into a CSV file and then save it into a folder on my computer.
Using Python, a relatively easy-to-learn coding language, some perseverance and lots of Stack Overflow searching, I managed to write a short program that did just that.
Step 1: Locating the data
First, let’s take a look at the webpage to see where these PDFs are stored. Here’s the link to all the weekly incident reports in 2019 on the B.C government website.
There’s a separate web page for every year, and each web page holds a list of links to the weekly incident reports PDFs. If you right-click on the web page and click “Inspect,” you can see how the page is formatted with HTML.
Each list item is held in a <li> tag. In each <li> tag is a link to the PDF that we want, and the links are held in <a href> tags.
Now that we know where our data is living on the web page, we have a better idea of how to go about identifying it and locating it in our code.
2. Setting up your workspace
Before we start writing our Python code, we need to have the code downloaded on our computer. This guide from RealPython will tell you how to properly install Python 3 on your computer.
Once you have Python installed, you’ll need to download a text editor to write your code in. A text editor is basically a program that allows you to write and edit a range of programming languages.
I use Atom for my work, but more simpler text editors include:
- SublimeText
- Notepad++
- Anaconda (A very popular text editor for using Python for data science)
Open up a new file and give it a name. I named my file scraperExample.py. Make sure to include the file extension “.py” so that your text editor knows that you’re writing in Python.
Now we can start writing some code!
3. Import packages
Python packages are sets of useful functions that contain a directory of pre-written modules. Using packages eliminates the need to write a lot of code from scratch.
Here’s a helpful guide on how to install packages on your computer from DataFish.
It took me a while to figure out which packages to use and which functions to use within the package. I looked up a lot of examples on Stack Overflow and other coding resources to see how other programmers use certain packages, and then applied bits of their code in my own project.
That being said, here’s a brief overview of the libraries we’re using:
- requests – allows you to send HTTP/1.1 requests
- tabula – can read tables of PDFs and convert a PDF file into CSV/TSV/JSON file
- Beautiful Soup – pulls data out of HTML and XML files
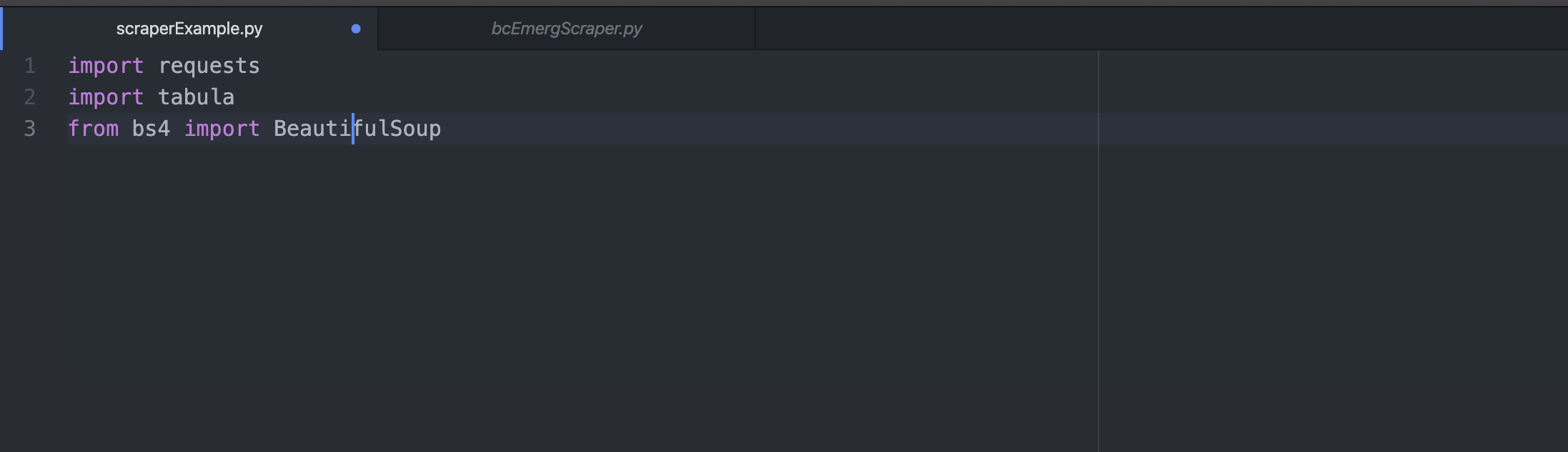
Once you’ve installed the packages on your computer, you just need to write “import (library name)” in the first lines of your file.
4. Identify the website to scrape from
After you’ve got your packages imported into your file, we need to start off by telling our scraper where we want to scrape from.
I created a variable called link that stored the URL of the BC government website with the weekly incident reports.
The headers variable contains the HTTP response headers. Frankly, I still don’t really know what headers are but I used Websniffer to get response headers for the website in question. Just know that to use the requests.get function, you’ll need a parameter for its headers.
I created another variable called request which will send an HTTP request to the URL we’ve identified and download the HTML contents of the web page for us we’ve just identified. The .get is a function we’ve pulled from the requests library that we imported earlier. It needs two parameters: the URL of the website and the headers, both of which we’ve just identified and assigned to variables.
Our variable request now holds the source code of our our link.
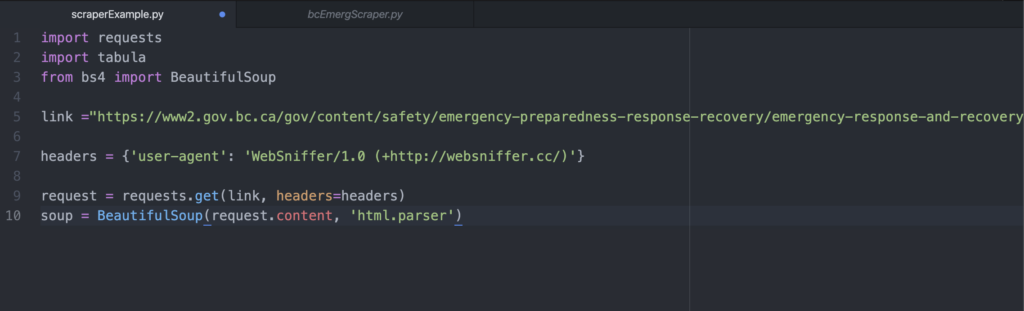
Now, we bring in Beautiful Soup to parse through our HTML data. Requests and Beautiful Soup are often used together in this order to request the HTML from the website and then identify certain tags we want from it.
The soup variable holds the contents of BeautifulSoup() function, which is essentially the HTML code of the web page we requested. The second parameter of the Beautiful Soup function ‘html.parser’ basically instruct Beautiful Soup to use the appropriate parser.
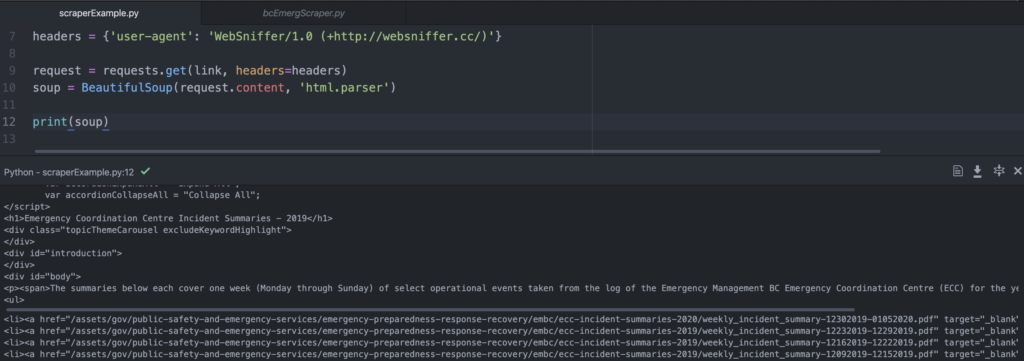
At this point, it’s a good idea to check that your code is working so far. To see if my soup variable actually captured the website HTML, I wrote the line “print (soup)” to print out the output of our soup variable.
Then, I run my code using Command + I on my Mac. Depending on what text editor you use, you might run your code differently. If all goes well, print(soup) should return all of the HTML content of the web page.
It’s not pretty, but it’s all there. This is the same HTML content we saw when we right-clicked “Inspect” on the web page. We can also see the <li> tags with the PDF links that we want.
4. Getting the PDF links
Right now, we have all of the HTML inside our soup variable, but we really only need the links to the PDFs. If you take a look at our printed HTML output, you can see that the link is stored in an <a href> tag inside a <li> tag.
Also, notice that the link isn’t the full link, but only the subdirectory of the website–or what comes after the backslash. This means the <a href> item doesn’t include “https://www2.gov.bc.ca” or the domain. But we’ll deal with that later.
Next, we’re going to parse through the HTML content to pick out the <a href> tags we want. As you might’ve seen, there are other links, and therefore other <a href> tags, besides the links to the PDF on the web page. To avoid scraping every single <a href> tag on the page, we have to zero in on the specific HTML container that our PDF links are nested in.
First, we have to find the right <div> tag to dig through. <Div> tags are basically containers for groups of HTML content, and the one that we want has an id of “body.” You can see how the <li> tags are nested within the “body” <div> on the website.
This makes it easy for us to tell Beautiful Soup to .find that exact div. The .find module is another function included in the Beautiful Soup package that helps us locate one specific HTML tag. We attach that to our soup variable, which stores our HTML content, and set the parameters to the “body” <div> item. We store our “body” <div> in a variable called bodyDiv.
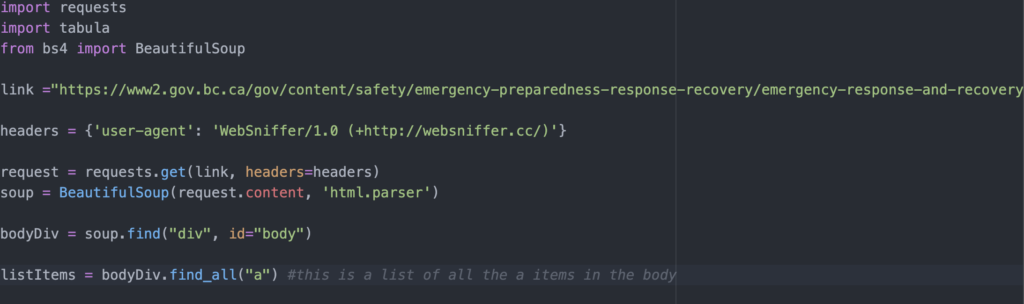
But, we’re not quite there yet. Within the bodyDiv variable, we need to grab all the <a href> tags. Beautiful Soup has another function called .find_all that returns a list of requested elements. This time, we’re telling Beautiful Soup to find all instances of “a” within bodyDiv.
Important: There are different data types in Python including lists, strings, integers and arrays. A list does not act the same as a string and a string doesn’t act the same as an integer. This W3School overview describes the differences between different Python data types.
Again, I like to print out my most recent variable to see if it’s captured what I intended it to. The listItems variable should store a list of all the <a href> tags in our “body” <div>.
Great, now we have a list of all the <a href> tags. But we only really need the bit that sits inside the quotation marks after the “href” parameter. This is the first list item we have in our listItems variable. We just need the highlighted part.
<a href=”/assets/gov/public-safety-and-emergency-services/emergency-preparedness-response-recovery/embc/ecc-incident-summaries-2020/weekly_incident_summary-12302019-01052020.pdf” target=”_blank”>December 30, 2019 – January. 5, 2019 (PDF)</a>
This next part is a bit tricky. What we’re trying to do is create a new list called links which will contain the full PDF URLs we need. First, we create an empty list by setting links = [] as there is nothing contained in the list, yet.
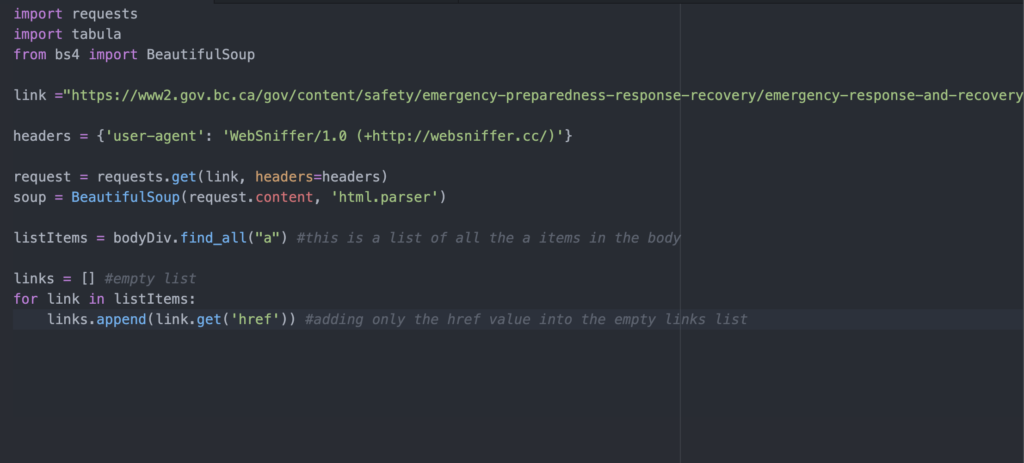
Next we use a for loop (read more about for loops at this W3School article) to do the following steps:
- Grabbing only the href value from our <a href> tags in our listItems list
- Appending (or adding) that href value into our empty links list
Our for loop will do those two steps for every item in our listItems list until completion. The for loop lets us iterate through the list in two lines of code instead of writing the same code for every single list item.
Now, if we print our links variable, we should get a list with just the PDF link.
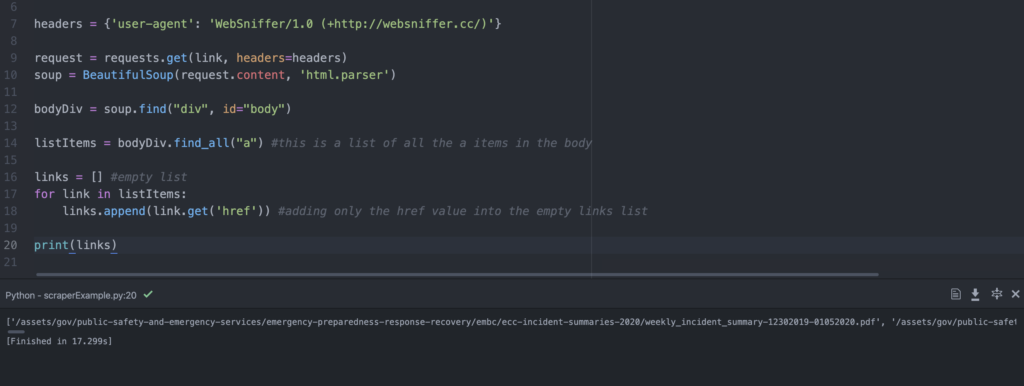
Great! But as we saw before, these are still missing the domain name–it’s not a full URL. Thankfully, since they all live on the same website (“https://www2.gov.bc.ca”) we just need to append all of our list items to that exact string (text).
In Python, to concatenate means to add two string objects together. We’re essentially concatenating the domain with every list item in our links list.
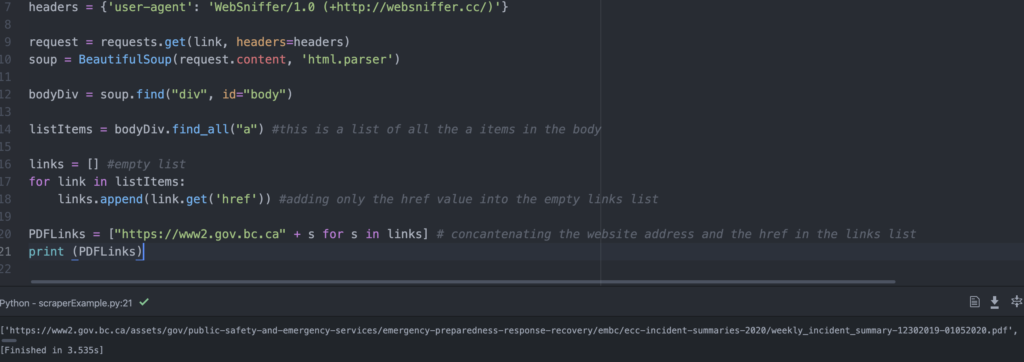
Our new variable PDFLinks stores a list where each list item starts with the string “https://www2.gov.bc.ca” and then we use list comprehension to take items from an existing list (our links list) and add every single item to our string.
This Stack Overflow discussion goes over list comprehension and saved me a lot of time during this step.
If we print PDFLinks, we finally get a list of our complete PDF URLs. Yay!
5. Downloading the PDFs and saving as CSVs
We have a list of the links we need. Now we need to write some code that goes to each URL, downloads the PDF, and then saves it as a CSV. This was by far the trickiest part of the code for me–figuring out how to automatically change the file name for every URL took me days to figure out. Without the help of my computer science friend, an extremely helpful CBC data journalist and Stack Overflow, I wouldn’t have been able figure this part out (while keeping my sanity).
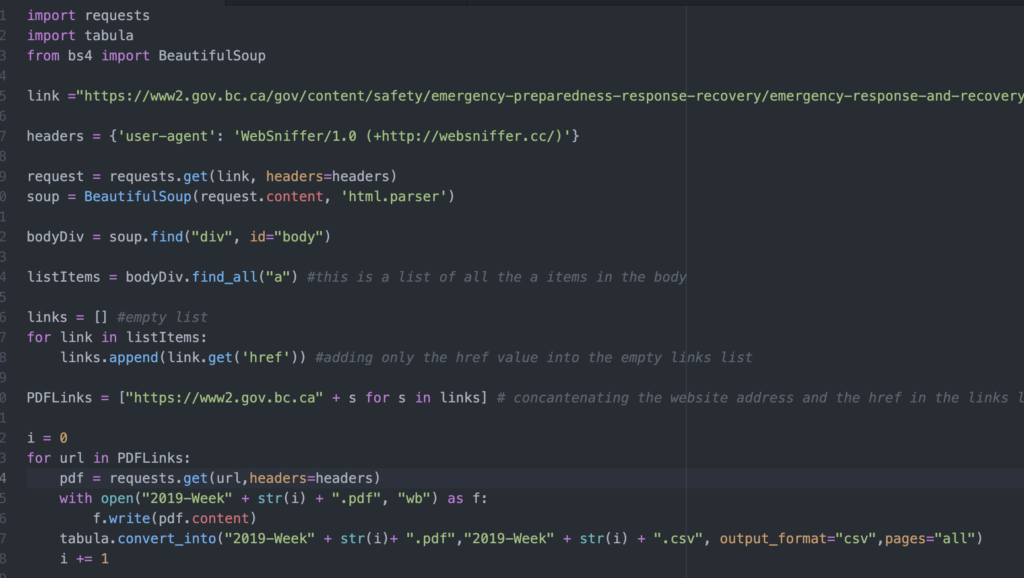
First we set a variable called i to 0 (as an integer, not a string) that acts as an iterator. Every time the for loop completes, we add 1 to i until we go through the entire list. This will make more sense later.
Inside our our for loop, we’re looking at every URL list item in our PDFLinks list. We created another variable called pdf that requests the source code for the URL. (Remember our handy requests.get function?)
Now that we’ve requested the contents of the first PDF URL in our PDFLinks list, we need to save it on our computer. In our with line, we’re creating and opening a file (represented as the variable f) using the open() function.
The name of our file is the string “2019-Week” plus (concatenated with) the STRING version of our current i value. The str() function converts an object from one data type, in this case, an integer, into a string so that we can manipulate it as if it was a string.
In our first iteration through our for loop, i would be 0.
So far, our file name is “2019-Week-0” and we add that with the string “.pdf” which denotes the file as a PDF file. We’ve created, named and opened the file which is represented as f.
Now we, use the .write function to insert the content of our pdf (which we requested earlier) into this newly made file. At this point in our code, we’ve just downloaded the PDF of the first link in our list!
Now within the same for loop, we have to convert the PDF into a CSV. We do this by using the tabula library that we imported at the beginning. The parameters of the tabula.convert_into function are as follows:
tabula.convert_into(“file we want to convert.pdf”, “output.csv”, output_format=”csv”, pages=’all’)
We simply reuse the same naming format we used to name our PDF (“2019-Week-” + str(i) + “.pdf”) to identify the PDF we want to convert, and name the CSV file the same thing, swapping the “.pdf” for “.csv.” The last two parameters makes sure that our output format is CSV and that we capture all the pages.
Now, we’ve successfully converted our PDF into CSV! But, we have to do this with every list item in our PDFLinks remember? To iterate through the loop again, while making sure every file name is different, we add 1 to our i index at the very end of our loop.
Now, our for loop will go through the exact same process for every URL, adding 1 to i as it completes each URL until we’ve reached the end of our list.
Let’s see it in action:
And that’s it! Now we have our data in a CSV format that we can do some more analysis on using pivot tables, filters and more spreadsheet functions. If you see the CSV file in the video, some of the tables are messed up since there were multiple tables of different dimensions in the PDF. It still needs some cleaning up… which may be a coding project for another time.
I worked on this very short piece of code on and off for almost a month, which sort of defeats the purpose of writing web scraping code.
But, the process of writing and debugging this code really reaffirmed my motivation to become more code-savvy. Working on projects like this, where you’re learning code as you’re building your solution, can be a great way to sharpen your skills in a language you might have some basic understanding of.
Web scraping can unlock new worlds of data for journalists if you know where to look. Interesting data can be hidden in lengthy annual reports or slide decks stored as PDFs on a website, or in HTML lists and tables on a random web page of a company website. Learning the basics of Python scraping and HTML can be a useful skill to add to your data journalist toolkit.

The province of Ontario is in borderline shambles battling COVID-19, and measures taken so far have been ineffective at best.
Premier Doug Ford recently announced and implemented new measures on Saturday to help battle the uptick in severe COVID-19 cases across the province, but more needs to be done to clean up the ongoing mess that has been created over negligence.
The numbers keep growing and the trend didn’t stop today. According to Ontario.ca, 95 new people were sent to the hospital including 14 who were administered into the ICU. Of those 14 new people, 10 are currently on a ventilator trying to battle the effects of COVID-19. Overall, there are currently 2,202 people in Ontario hospitalized with the virus.
In response to this trend, the province enhanced measures by forbidding people to gather outdoors with members of other households, non-essential construction was put on pause, and outdoor sporting facilities/playgrounds are momentarily restricted.
While there is a recent uproar from the people in response to the provincial government’s handling of the pandemic, due to the lack of consistency in terms of what is and isn’t deemed essential, multiple issues could be traced back to well beyond just the past month.
Issues concerning the spread of the virus can be dotted back to different decisions made by the government, whether that be the decision to send students to school for the majority of the 2020-21 school year, the decision to briefly re-open patio dining back in March, or even making people work high-risk jobs without real necessity.
The concept of what is and isn’t essential has been confusing for Ontarians everywhere, and the inconsistencies in applying proper safety measures has cost thousands of lives up to this point, which is reflected in the 7,735 COVID-19 related deaths in the province up to this point.
And with different variants wreaking havoc across the country, it’s only a matter of time before things get even worse here. Vaccinations across the country are increasing, but Canada still has catching up when compared to some of the top vaccinating nations on the planet.
Despite the emergence of vaccinations growing across the province, ICUs are still being hammered with new patients, and it’s only a matter of time before most facilities begin to tap out in terms of capacity.
With thousands of new cases a day, there needs to be actual change. The province led by Doug Ford has danced around too many ineffective measures, causing serious problems today.
While vaccinations are on the upswing, and more Ontarians are getting immunized, it isn’t going to solve the problem until most people are vaccinated, and with improper behaviour, it will continue to cost more lives until further notice.
Until Canada can catch up with vaccinations as they are expected to, Ontario needs to put the people before the money. It will require tough challenges to swallow, but it’s necessary if we really care about saving lives.
For the first time in the 21st century, the Toronto Maple Leafs look to be serious Stanley Cup contenders. On trade deadline day, Kyle Dubas, Leafs general manager, pushed all the chips in to solidify his team.
The Leafs currently sit in first place in the Scotiabank North Division with 60 points in 44 games, a three-point lead over the Winnipeg Jets, who sit in second place.
One player that has been a part of their success is Auston Matthews, who in 40 games this year has 32 goals. With that total, he sits first in the league for goals scored with a six-goal lead, despite missing four games due to multiple injuries.
At this pace, he would score 44 goals in a 56-game season.
As we inched closer to the deadline, it was clear that the team should shore up their depth, especially in the forward position.
In a press conference on March 16, Dubas said, “I think it’s very clear that our team will explore every opportunity to improve.” He added that most of their trade conversations centered around forwards.
When the Leafs traded for Nick Foligno on April 11th, Dubas filled that need perfectly. A winger who can play up and down the lineup and will get in puck battles most don’t like to.
It should be clear to fans that Kyle Dubas was not messing around this year. In years past, Dubas has only made moves that the team needed, like trading for Jack Campbell, a backup goalie. Which the team desperately needed.
After last year’s embarrassing loss to David Ayres, Dubas made the decision to not make many moves at the deadline. He even went as far as taking back a contract offer to defensemen Zach Bogosian, who had just been released from the Buffalo Sabres.
Nick Foligno also sees something with this team. While there were multiple teams in on him, he chose to come to Toronto.
In his first media availability, he said, “I’m really looking forward to just getting there and getting acquainted with everything and then hitting the ground running and helping any way I can.”
On deadline day, the Leafs also acquired goaltender David Rittich from the Calgary Flames and defensemen Ben Hutton from the Anaheim Ducks.
**Statistics updated up to April 17th, 2021
-

 Lifestyle3 years ago
Lifestyle3 years ago‘I love you so much it hurts’: Domestic Violence Awareness & Resources
-

 Uncategorized3 years ago
Uncategorized3 years agoThe NBA’s fight against COVID-19
-

 Uncategorized3 years ago
Uncategorized3 years agoThe Raptors’ NBA title window is closed
-

 Sports3 years ago
Sports3 years agoFred VanVleet drops 54 points, breaks Raptors franchise record
-

 Uncategorized3 years ago
Uncategorized3 years agoA simple Python web scraping guide for journalists
-

 Uncategorized3 years ago
Uncategorized3 years agoNorth Shore Rescue sees a busy winter season with a record-breaking 2020
-
Uncategorized3 years ago
Ontario is currently in shambles with COVID-19
-

 News3 years ago
News3 years agoSuper Bowl LV breaks records